באחת הקבוצות שאני עוקב אחריהן בפייסבוק, פורסם פוסט בו שאל מישהו איך הוא יכול לעקוב אחרי שינויים שנעשים בטבלאות השמורות ב- SQL Server, כדי להעביר את המידע לדטאבייס אחר. לכאורה, אירוע פשוט ולא מורכב במיוחד שכבר כתבתי עליו בעבר. אבל, לשואל הנ"ל היו כמה דרישות קצת פחות טריוויאליות:
- מדובר בטבלאות שמכיל מידע שמשתנה, ולא רק מתווסף (ולכן "crawling" על עמודת ID לא מספיק)
- אין עמודות עם זמני השינוי בטבלאות
- הוא לא יכול להשתמש ב- CDC, או להגדיר כל דבר נוסף ברמת הדטאבייס (הוצעו לו בתגובות טריגרים וכו', אבל זה פתרון שלא מתאפשר מבחינתם).
מדובר במצב קצת טריקי, שהוביל למספר הצעות של העתקת כל המידע לשירות אחר וביצוע ההצלבות שם, שימוש ב- query engine כלשהו שמאפשר שליפה פדרטיבית (כמו Trino או Redshift) כדי לעשות JOIN בין ה- DB שאליו הוא מכניס את המיעד ל-DB המקור וכו'.
בהחלט יכול להיות שהפתרונות הללו הם הפתרונות ההגיוניים. אבל, תוך כדי חשיבה על הבעייה הזאת, תהיתי האם ניתן לממש "change tracking" עצמאי ומה תהיה המשמעות של זה. מאד יכול להיות שמבחינות שונות הפתרון שאני עומד להציע בפוסט הזה לא משתלם למימוש (במיוחד אם ה- DB קטן, ואז קל להעתיק כל פעם או לעשות שליפות שמצליבות כל פעם מחדש את המידע), אבל הוא מעניין טכנולוגית.
אז מה הפתרון?
אני עומד להסתמך (ולקוות) שיש ל-DB הנ"ל גיבויים ושה- DB מוגדר בתור Recovery Model של Full, כלומר שמתבצעים גיבויי transaction log. אני גם מקווה ששואל השאלה יוכל לגשת לגיבויים הללו (למרות שקיימת אפשרות גם בלי, ונדבר עליה גם בהמשך).
כדי להבין את גרעין הפתרון, צריך לדעת דבר אחד על ה- Transaction log file: כל שינוי נכתב אליו, לפני שהתבצע ב- data files.
במקרה שמוגדר Full recovery model, זה אומר שהשינויים נשמרים בו גם עד שמתבצע transaction log backup. כלומר, אם נקרא את התוכן של ה- transaction log, נוכל לדעת מה היו השינויים (וכך האפליקציה תוכל לעשות בהם שימוש).
כלומר, הרעיון יכלול את השלבים הבאים:
- נאסוף את כלל קבצי ה- transaction log backups שמתבצעים
- על כל קובץ נריץ סקריפט, שמוציא את המידע על השורות שבהן בוצע השינוי
- נרצה לחלץ את ה- ID-ים (כלומר, את ערכי ה- primary key של השורה, כדי לזהות אותה חח"ע) מה- transaction log, ואז להשתמש באותם ערכים כדי להריץ שליפה מול ה- DB ולהביא את הערכים הנכונים.
איך אנחנו יכולים לעשות את זה? פה באות לידי ביטוי כמה פונקציות מתועדות יותר ופחות שמאפשרות לנו לגשת קצת ל-"מאחורי הקלעים" של הדטאבייס ולתשאל את ה- storage engine ישירות לתוכן של דף, או לקרוא את התוכן של ה- transaction log.
שלב א': בואו נקרא את התוכן של ה- transaction log
כדי לקרוא את התוכן של transaction log נוכחי אנחנו יכולים לעשות שימוש בפונקציה fn_dblog. כדי לקרוא תוכן של קובץ גיבוי של ה- transaction log, אנחנו יכולים להשתמש בפונקציה fn_dump_dblog שמקבלת מלא פרמטרים, שמרובם לא ממש אכפת לנו:
SELECT [Current LSN] as LSN, Operation, Context, [Page ID] as PageId
FROM fn_dump_dblog(NULL, NULL, 'DISK', 1, N'c:\tmp\dates\20250120\l1.bak',DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT)
WHERE Operation IN ('LOP_MODIFY_ROW', 'LOP_INSERT_ROWS', 'LOP_MODIFY_ROW') AND Context = 'LCX_CLUSTERED'
והתוצאה נראית כך:
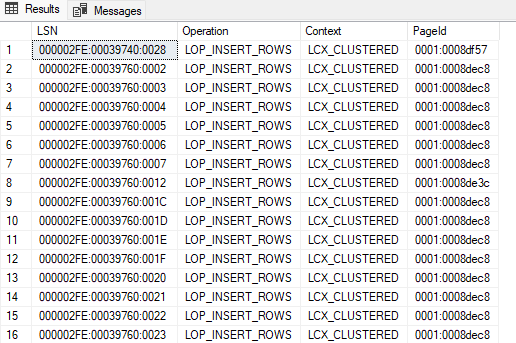
נשים לב שאנחנו מתמקדים בסוגי פעולות מסויימות (שעניינו את כותב הפוסט המקורי – הוספה ועדכון, יכול להיות שאתם תתעניינו בפעולות נוספות) ושלכל log record יש לנו את ה- PageId שהושפע. מזהה ה- page מורכב ממזהה הקובץ, נקודותיים ואז מזהה ה- page בהקסה. לשלב הבא, אנחנו צריכים להמיר אותו לדצימלי.
שלב ב': לקרוא תוכן של page
כדי לקרוא תוכן של page, נשתמש בפקודה DBCC PAGE:
DBCC PAGE ('SO-2016',1,581463,3) WITH TABLERESULTS
וככה נראית התוצאה:
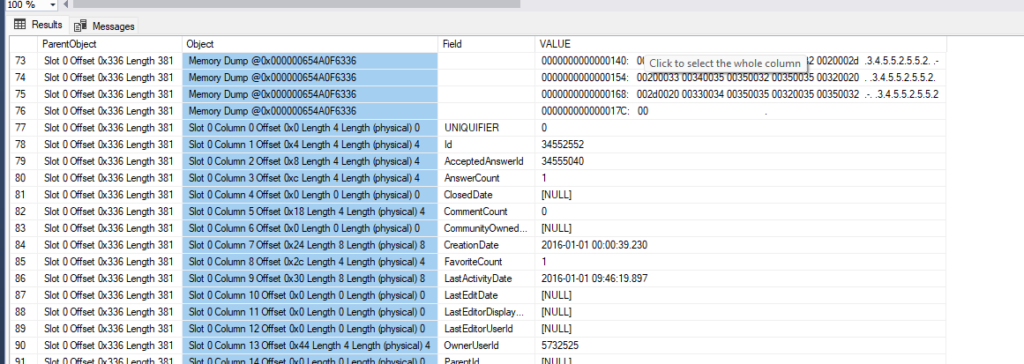
נשים לב שאנחנו ממש יכולים לראות תוכן של שורה שמושפעת. בתוך כל page מופיע גם ה- object_id שמשוייך לטבלה שאליה שייך ה- page (ב- page יחיד לא יכול להתערבב מידע מטבלאות שונות), מה שיכול לשמש אותנו לקשר את המידע לטבלה ומשם ל- metadata כמו מי ה- PK-ים שלפיהם אנחנו עומדים לשלוף.
שלב ג': נבנה שליפה דינמית ונביא מהטבלה את הערך העדכני של השורה
אמנם אפשר לחלץ את כל הערכים מה- transaction log, אבל זה ידרוש להתמודד עם מספר מקרי קצה מגעילים (למשל: overflow pages, או במקרה של heap-ים להתמודד עם forwarded records). הרבה יותר קל (גם אם פחות יעיל) לחלץ רק את המזהה החזק של השורה (ה- primary key), ואז לבצע את השליפה מול ה- DB עצמו כדי להביא את המידע המלא של השורה.
סקריפט לדוגמא
כדי לארוז את הכל ביחד (לפחות מספיק כדי להסביר את הדוגמא הנוכחית), הסקריפט powershell הבא מבצע את השלבים הללו בצורה אוטומטית בהינתן transaction log backup ובהינתן העובדה ששם עמודת ה- PK קבוע.
param (
[Parameter(Mandatory = $true)]
[string]$LogBackupPath,
[Parameter(Mandatory = $true)]
[string]$ServerName,
[Parameter(Mandatory = $true)]
[string]$DatabaseName
)
#if not installed, execute: install-module -name dbatools -scope currentuser
Import-Module dbatools -ErrorAction Stop
Set-DbatoolsConfig -FullName sql.connection.trustcert -Value $true -Register
Set-DbatoolsConfig -FullName sql.connection.encrypt -Value $false -Register
$pkColumnName = "Id" #in real world it would be configurable, or dynamically detected
$allTablesQuery = "SELECT name, object_id FROM sys.tables"
$tablesList = Invoke-DbaQuery -SqlInstance $ServerName -Database $DatabaseName -Query $allTablesQuery
$transactionLogContentQuery = @"
SELECT [Current LSN] as LSN, Operation, Context, [Page ID] as PageId
FROM fn_dump_dblog(NULL, NULL, 'DISK', 1, N'$LogBackupPath',DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT)
WHERE Operation IN ('LOP_MODIFY_ROW', 'LOP_INSERT_ROWS', 'LOP_MODIFY_ROW') AND Context = 'LCX_CLUSTERED'
"@
$transactionLogContent = Invoke-DbaQuery -SqlInstance $ServerName -Database $DatabaseName -Query $transactionLogContentQuery
$processedPages = [System.Collections.Generic.HashSet[string]]::new()
$processedIds = [System.Collections.Generic.HashSet[string]]::new()
foreach ($trow in $transactionLogContent) {
if ($processedPages.Contains($trow.PageId)) {
continue
}
$pageIdSplitted = $trow.PageId.Split(':')
$pageId = $pageIdSplitted[1]
$fileId = $pageIdSplitted[0]
$pageIdNum = [Convert]::ToInt32($pageId, 16)
$pageInfoQuery = "dbcc page ('$DatabaseName',$fileId,$pageIdNum,3) WITH TABLERESULTS"
$pageInfo = Invoke-DbaQuery -SqlInstance $ServerName -Database $DatabaseName -Query $pageInfoQuery
$pageGroupedByParent = $pageInfo | Group-Object -Property ParentObject
$tableObjectId = ($pageInfo | Where-Object { $_.Field -eq "Metadata: ObjectId" }).Value
$tableName = (($tablesList | Where-Object { $_.object_id -eq $tableObjectId }) | Select-Object -First 1).Name
$currentRow = @{}
$currentSlot = $null
foreach ($parentGrp in $pageGroupedByParent) {
if ($parentGrp.Name.StartsWith("Slot ") -eq $false) {
continue
}
if ($parentGrp.Name -ne $currentSlot) {
if ($null -ne $currentSlot) {
$pkColumnValue = $currentRow[$pkColumnName]
$rowId = "$tableName-$pkColumnValue"
if ($processedIds.Contains($rowId) -eq $false) {
$dbQuery = "SELECT TOP 1 * FROM $tableName WHERE $pkColumnName=$pkColumnValue"
Write-Host "Finished processing row content, going to fetch the current state from DB with query: $dbQuery"
$updatedRowData = (Invoke-DbaQuery -SqlInstance $ServerName -Database $DatabaseName -Query $dbQuery) | Select-Object -First 1
Write-Host "This is a row that was affected in this transaction log backup: $($updatedRowData| Select-Object * -ExcludeProperty ItemArray, Table, RowError, RowState, HasErrors | ConvertTo-Json)"
$processedIds.Add($rowId) | Out-Null
}
$currentRow = @{}
}
$currentSlot = $parentGrp.Name
}
foreach ($field in $parentGrp.Group) {
if ($field.Field -ne "" -and $field.Object -clike "Slot * Column *") {
$currentRow[$field.Field] = $field.Value
}
}
}
Write-Host "Done processing file '{$fileId}' page '$pageIdNum'"
$processedPages.Add($trow.PageId) | Out-Null
}
פערים במימוש הנוכחי
בפתרון הנ"ל, במימוש שהצגתי, יש כמה חסרונות, שאם מישהו שוקל לעשות בו שימוש מלא ואמיתי כנראה יצטרך לחשוב עליהם ולפתור לפחות את חלקם:
- אנחנו עומדים להתייחס לשורות שלא התעדכנו בפועל, בתור שורות שכן התעדכנו.
מידע ב- SQL Server נשמר בגרנולריות של page, שגודלו תמיד כ- 8KB. ב- transaction log, אנחנו יכולים לחלץ בקלות מי ה- page שבו בוצע השינוי. אנחנו גם יכולים יחסית בקלות להביא את התוכן של אותו ה- page. מה שאנחנו לא יכולים לעשות באותה הקלות, זה לפרסר ולהבין ממש מי השורה שבה התבצע השינוי. מכיוון שהמטרה של השואל המקורי הייתה לזהות שורות שבהן היה שינוי כדי להעביר אותן לתשתית DB אחרת, ומכיוון שכל החלופות שלו במילא מערבות העתקה מאסיבית של מידע לתשתית ה- DB האחרת (בין אם זמנית, לטובת התשאול, ובין אם קבועה של העתקה כל פעם מחדש) – זה עדיין חסכוני. - קיימים מספר מצבים נוספים שבהם אנחנו נזהה במימוש נאיבי page ככזה שהתבצע בו עדכון, למרות שלא השתנה כלום: למשל, מצב שבו טרנזקציה רצה ועשתה שינויים, ולאחר מכן עשתה rollback. אמנם ניתן לסבך קצת את המימוש כדי להתמודד עם זה, אבל מכיוון שטרנזקציה יכולה להיפרס בין קבצי גיבוי שונים, שאנחנו לא נראה ביחד, התמודדות מלאה עם המצב הזה תדרוש שמירת state בין ריצות.
- אנחנו עומדים לבצע מספר רב של תשאולים (על כל שורה שהשתנתה בקובץ שאנחנו עוברים עליו עכשיו). זה לא בעייה מובנית, אלא פשוט נובעת מהמימוש הנאיבי. במימוש קצת יותר מתוחכם, אפשר לעשות batching של הפניות ולשלוף בבת אחת אוספים של שורות שהשתנו.
- אנחנו לא מתמודדים עם overflow pages: כאשר משתמשים ב- varchar(n) או nvarchar(n) ונגמר המקום ב- page, SQL Server יכול להחליט להקצות page נפרד, במקום אחר ב-data file, שבו יישמר המידע בפועל. במקרה כזה, נשמר ב- page המקורי רק pointer ל- overflow page. במצב שבו ה- page שמכיל את השורה עצמה השתנה (התעדכן ה- pointer או ערך אחר), הפתרון שהצגתי עדיין יעבוד בצורה תקינה. מכיוון שאנחנו שולפים את המצב הנוכחי של השורה עם שליפה רגילה, פשוט נקבל את הערכים האמיתיים. אבל, הקוד הנוכחי לא מתמודד עם מצב שבו התעדכן רק ה- overflow page ללא שינוי בשורה עצמה.
- בדקתי את המימוש רק מול טבלה עם clustered index, ייתכן שיידרשו התאמות מסויימות לעבודה עם heap-ים
כמובן, שמעבר לכך, כדי להפוך את המימוש הנ"ל למבצעי צריך לדאוג לניטור ולהתמודדות עם מקרים שעלולים לקרות (ועדיף שנוכל להשתקם מהם אוטומטית). למשל, מה קורה אם איבדנו קובץ גיבוי באמצע. ניתן לזהות את המצב הזה באמצעות פער ב- LSN, ובמקרה כזה, למשל, לייצר מחדש העתקה מלאה של המידע.
כתיבת תגובה